

Обновления в реальном времени звучат модно, но по сути это обычная реакция системы на события «здесь и сейчас»: клик пользователя, платёж, датчик на заводе, лог сервера. Не как раньше: собрали логи за день, запустили ночной отчёт и утром посмотрели результат. Сейчас обработка потоковых данных в реальном времени нужна, чтобы менять интерфейс, цены, рекомендации и алерты по ходу игры, а не задним числом. Главное отличие — данные не «лежат» в хранилище, а непрерывно текут сквозь сервисы, и эти сервисы должны успевать думать на лету, без долгих пауз и пересчётов.
Ключевые термины без академического занудства

Чтобы говорить на одном языке, разберёмся в базовых понятиях. «Поток данных» — это бесконечная последовательность событий, где каждое событие маленькое и живёт недолго само по себе, ценность появляется в совокупности. «Стриминговая обработка» — когда каждое событие обрабатывается по мере поступления, почти мгновенно. «Real-time» в жизни — это не всегда миллисекунды, а скорее гарантированный отклик в пределах бизнес‑требований: от долей секунды до пары минут. «Платформа для стриминговой обработки данных» — это связка брокера сообщений, вычислительного движка и хранилища, которая позволяет не возиться с низкоуровневой инфраструктурой.
Как выглядит потоковая архитектура (диаграмма словами)
Типичная схема напоминает конвейер. [Диаграмма: слева «Источник событий» (веб‑серверы, мобильные приложения, датчики) стрелками бьют в «Брокер сообщений (Kafka, Pulsar)». От него несколько стрелок идут в «Стриминговый движок (Flink, Spark Streaming)». Далее две ветки: вверх — «Онлайн‑сервисы и дашборды», вниз — «Хранилище (Data Lake / DWH) для анализа».] На каждом этапе можно фильтровать, агрегировать, обогащать события. Системы real-time analytics для бизнеса часто добавляют поверх этого ещё слой API и визуализации, чтобы аналитики и продакты не лезли в код, а работали через понятные им интерфейсы и готовые виджеты.
Чем real-time отличается от пакетной обработки
Пакетная модель: вы накопили гигабайты данных, по расписанию запустили job, через час получили отчёт. Стриминговая: данные не ждут, job по сути вечная и крутится постоянно. [Диаграмма: сверху «Batch» — прямоугольники «Сбор → Обработка → Отчёт» повторяются блоками; снизу «Stream» — непрерывная линия «События → Стриминг‑движок → Результаты».] Для компаний важно трезво сравнивать аналоги: там, где нужны отчёты раз в сутки, real-time — лишняя сложность. Но когда речь о фрод‑мониторинге, динамическом ценообразовании или алертах на инциденты, решения для обработки данных в реальном времени для компаний дают совсем другой уровень управляемости рисками и возможностями.
Инструменты: от Kafka до Flink без мистики
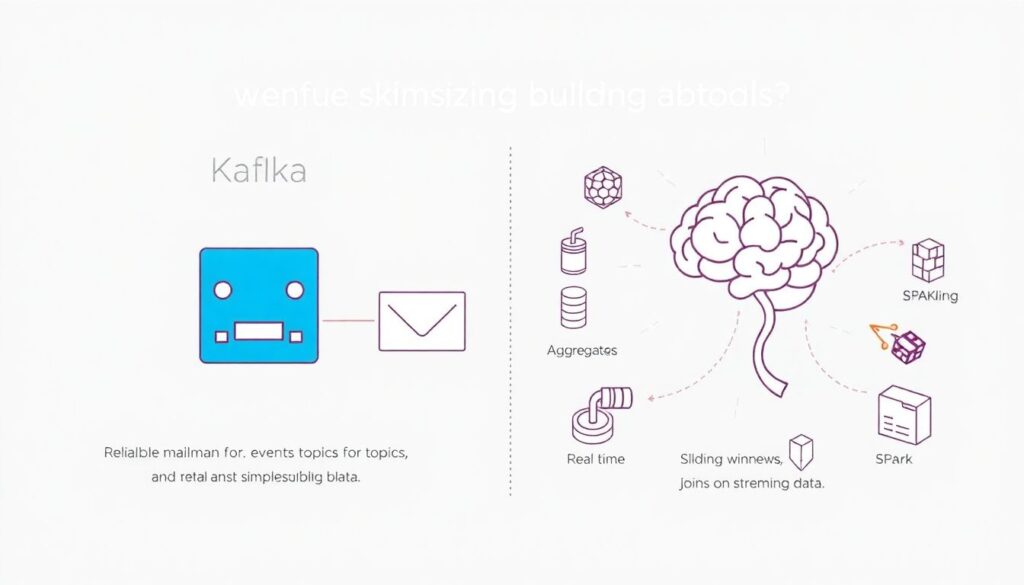
Новички часто боятся названий, но инструменты для обработки потоковых данных kafka flink — это просто кирпичи. Kafka — надёжный «почтальон» для событий: принимает, складывает по топикам, раздаёт подписчикам. Flink — «мозг», который считает агрегаты, скользящие окна, джоины в потоке. Есть аналоги: Spark Structured Streaming, Apache Pulsar, Redpanda, облачные managed‑решения вроде Kinesis или Pub/Sub. Важно понимать не бренд, а паттерн: брокер обеспечивает доставку и масштабирование, а движок — бизнес‑логику. Тогда замена конкретного инструмента — эволюционный шаг, а не катастрофа с миграцией всего стека.
Частые ошибки новичков в потоковой обработке
1. Игнорирование семантики доставки. «At‑least‑once», «at‑most‑once», «exactly‑once» кажутся теорией, но потом в отчёте внезапно появляются дубли, а пользователю дважды списывают деньги.
2. Путаница между временем события и временем обработки: опоздавшие сообщения ломают метрики, если не настроены окна и watermarks.
3. Отсутствие ретраев и DLQ: любое нестандартное событие превращается в падение job.
4. Обработка «как в batch»: тяжёлые join’ы, огромные состояния без продуманной очистки.
5. Слепая вера в «реальное время», без измерения latency и SLA, из‑за чего бизнес ждёт невозможного.
Практические советы и выводы
Чтобы платформа для стриминговой обработки данных не превратилась в бесконечный эксперимент, полезно начинать с узких, но измеримых кейсов: онлайн‑мониторинг ключевых метрик, простые алерты, базовые дашборды. Постепенно можно наращивать сложность логики и интеграций, опираясь на реальные потребности. Хороший ориентир — когда системы real-time analytics для бизнеса не живут отдельно, а питают CRM, recommendation engine, антифрод и операционные панели. Тогда обработка потоковых данных в реальном времени перестаёт быть «игрушкой инженеров» и становится обыденной частью принятия решений, где задержка измеряется секундами, а не сутками.